publications
2026
-
 Match or Replay: Self Imitating Proximal Policy OptimizationGaurav Chaudhary, Laxmidhar Behera, and Washim Uddin Mondalarxiv preprint, 2026
Match or Replay: Self Imitating Proximal Policy OptimizationGaurav Chaudhary, Laxmidhar Behera, and Washim Uddin Mondalarxiv preprint, 2026Reinforcement Learning (RL) agents often struggle with inefficient exploration, particularly in environments with sparse rewards. Traditional exploration strategies can lead to slow learning and suboptimal performance because agents fail to systematically build on previously successful experiences, thereby reducing sample efficiency. To tackle this issue, we propose a self-imitating on-policy algorithm that enhances exploration and sample efficiency by leveraging past high-reward state-action pairs to guide policy updates. Our method incorporates self-imitation by using optimal transport distance in dense reward environments to prioritize state visitation distributions that match the most rewarding trajectory. In sparse-reward environments, we uniformly replay successful self-encountered trajectories to facilitate structured exploration. Experimental results across diverse environments demonstrate substantial improvements in learning efficiency, including MuJoCo for dense rewards and the partially observable 3D Animal-AI Olympics and multi-goal PointMaze for sparse rewards. Our approach achieves faster convergence and significantly higher success rates compared to state-of-the-art self-imitating RL baselines. These findings underscore the potential of self-imitation as a robust strategy for enhancing exploration in RL, with applicability to more complex tasks.
@article{chaudhary2026matchreplayselfimitating, title = {Match or Replay: Self Imitating Proximal Policy Optimization}, author = {Chaudhary, Gaurav and Behera, Laxmidhar and Mondal, Washim Uddin}, journal = {arxiv preprint}, year = {2026}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, url = {https://arxiv.org/abs/2603.27515}, } -
 TEACH: Temporal Variance-Driven Curriculum for Reinforcement LearningGaurav Chaudhary and Laxmidhar BeheraInternational Conference on Autonomous Agents and Multiagent Systems, 2026
TEACH: Temporal Variance-Driven Curriculum for Reinforcement LearningGaurav Chaudhary and Laxmidhar BeheraInternational Conference on Autonomous Agents and Multiagent Systems, 2026Reinforcement Learning (RL) has achieved significant success in solving single-goal tasks. However, uniform goal selection often results in sample inefficiency in multi-goal settings where agents must learn a universal goal-conditioned policy. Inspired by the adaptive and structured learning processes observed in biological systems, we propose a novel Student-Teacher learning paradigm with a Temporal Variance-Driven Curriculum to accelerate Goal-Conditioned RL. In this framework, the teacher module dynamically prioritizes goals with the highest temporal variance in the policy’s confidence score, parameterized by the state-action value (Q) function. The teacher provides an adaptive and focused learning signal by targeting these high-uncertainty goals, fostering continual and efficient progress. We establish a theoretical connection between the temporal variance of Q-values and the evolution of the policy, providing insights into the method’s underlying principles. Our approach is algorithm-agnostic and integrates seamlessly with existing RL frameworks. We demonstrate this through evaluation across 11 diverse robotic manipulation and maze navigation tasks. The results show consistent and notable improvements over state-of-the-art curriculum learning and goal-selection methods.
@article{chaudhary2025teach, title = {TEACH: Temporal Variance-Driven Curriculum for Reinforcement Learning}, author = {Chaudhary, Gaurav and Behera, Laxmidhar}, journal = {International Conference on Autonomous Agents and Multiagent Systems}, year = {2026}, }
2025
-
 From Novelty to Imitation: Self-Distilled Rewards for Offline Reinforcement LearningGaurav Chaudhary and Laxmidhar BeheraTransactions on Machine Learning Research, 2025
From Novelty to Imitation: Self-Distilled Rewards for Offline Reinforcement LearningGaurav Chaudhary and Laxmidhar BeheraTransactions on Machine Learning Research, 2025Offline Reinforcement Learning (RL) aims to learn effective policies from a static dataset without requiring further agent environment interactions. However, its practical adop- tion is often hindered by the need for explicit reward annotations, which can be costly to engineer or difficult to obtain retrospectively. To address this, we propose ReLOAD (Reinforcement Learning with Offline Reward Annotation via Distillation), a novel re- ward annotation framework for offline RL. Unlike existing methods that depend on complex alignment procedures, our approach adapts Random Network Distillation (RND) to gen- erate intrinsic rewards from expert demonstrations using a simple yet effective embedding discrepancy measure. First, we train a predictor network to mimic a fixed target network’s embeddings based on expert state transitions. Later, the prediction error between these networks serves as a reward signal for each transition in the static dataset. This mechanism provides a structured reward signal without requiring handcrafted reward annotations. We provide a formal theoretical construct that provides insights into how RND prediction errors effectively serve as intrinsic rewards by distinguishing expert-like transitions. Experiments on the D4RL benchmark demonstrate that ReLOAD enables robust offline policy learning and achieves performance competitive with traditional reward-annotated methods.
@article{chaudhary2025from, title = {From Novelty to Imitation: Self-Distilled Rewards for Offline Reinforcement Learning}, author = {Chaudhary, Gaurav and Behera, Laxmidhar}, journal = {Transactions on Machine Learning Research}, issn = {2835-8856}, year = {2025}, url = {https://openreview.net/forum?id=F5K94JI2Jb}, } -
 MOORL: A Framework for Integrating Offline-Online Reinforcement LearningGaurav Chaudhary, Washim Uddin Mondal, and Laxmidhar BeheraTransactions on Machine Learning Research, 2025
MOORL: A Framework for Integrating Offline-Online Reinforcement LearningGaurav Chaudhary, Washim Uddin Mondal, and Laxmidhar BeheraTransactions on Machine Learning Research, 2025Sample efficiency and exploration remain critical challenges in Deep Reinforcement Learn- ing (DRL), particularly in complex domains. Offline RL, which enables agents to learn optimal policies from static, pre-collected datasets, has emerged as a promising alternative. However, offline RL is constrained by issues such as out-of-distribution (OOD) actions that limit policy performance and generalization. To overcome these limitations, we propose Meta Offline-Online Reinforcement Learning (MOORL), a hybrid framework that unifies offline and online RL for efficient and scalable learning. While previous hybrid methods rely on extensive design components and added computational complexity to utilize offline data effectively, MOORL introduces a meta-policy that seamlessly adapts across offline and online trajectories. This enables the agent to leverage offline data for robust initialization while utilizing online interactions to drive efficient exploration. Our theoretical analysis demonstrates that the hybrid approach enhances exploration by effectively combining the complementary strengths of offline and online data. Furthermore, we demonstrate that MOORL learns a stable Q-function without added complexity. Extensive experiments on 28 tasks from the D4RL and V-D4RL benchmarks validate its effectiveness, showing con- sistent improvements over state-of-the-art offline and hybrid RL baselines. With minimal computational overhead, MOORL achieves strong performance, underscoring its potential for practical applications in real-world scenarios.
@article{chaudhary2025moorl, title = {{MOORL}: A Framework for Integrating Offline-Online Reinforcement Learning}, author = {Chaudhary, Gaurav and Mondal, Washim Uddin and Behera, Laxmidhar}, journal = {Transactions on Machine Learning Research}, issn = {2835-8856}, year = {2025}, url = {https://openreview.net/forum?id=PHsfZnF2FC}, }
2024
-
 UniInsertion: A Unified Model-based Insertion Skill Learning via Differentiable Physics-based SimulationChenrui Tie, Wang Debang, Gaurav Chaudhary, and 5 more authorsOpenReview, 2024
UniInsertion: A Unified Model-based Insertion Skill Learning via Differentiable Physics-based SimulationChenrui Tie, Wang Debang, Gaurav Chaudhary, and 5 more authorsOpenReview, 2024Manipulating and inserting deformable objects into tight spaces remains challenging in robotics due to their flexibility, intricate configurations, and complex contact dynamics. Prior methods relying on analytical models or human demonstrations often struggle to generalize across diverse scenarios. This paper presents a model-based framework leveraging differentiable physics simulation and the innovative concept of \enquotelearning from reversal to enable robotic insertion of both rigid and deformable objects. Our key insight is that while insertion presents difficulties, the reverse process of insertion can provide clearer intermediate waypoints, and we posit that frames with a higher number of collision points during the insertion process are more likely to represent critical waypoints. By discerning these waypoints through learning from reversals, we obtain a smooth, differentiable transition from waypoint identification to trajectory optimization via the differentiable simulator. Furthermore, we construct an extensive dataset with the simulator, encompassing diverse object shapes, materials, and container geometries, with corresponding demonstrations. This powers imitation learning to train robust policies, showcasing adaptability to novel objects and containers. Our framework, integrating learning from reversals, differentiable physics, and imitation learning, pioneers a paradigm shift in robotic insertion capabilities. Evaluations demonstrate superiority over competing approaches in sample efficiency, performance, and sim-to-real transfer.
@article{tie2024uniinsertion, title = {UniInsertion: A Unified Model-based Insertion Skill Learning via Differentiable Physics-based Simulation}, author = {Tie, Chenrui and Debang, Wang and Chaudhary, Gaurav and Peng, Weikun and Chen, Tianyi and Yang, Gang and Mu, Yao and Shao, Lin}, journal = {OpenReview}, year = {2024}, url = {https://openreview.net/forum?id=RIk0DJIO8O}, }
2023
-
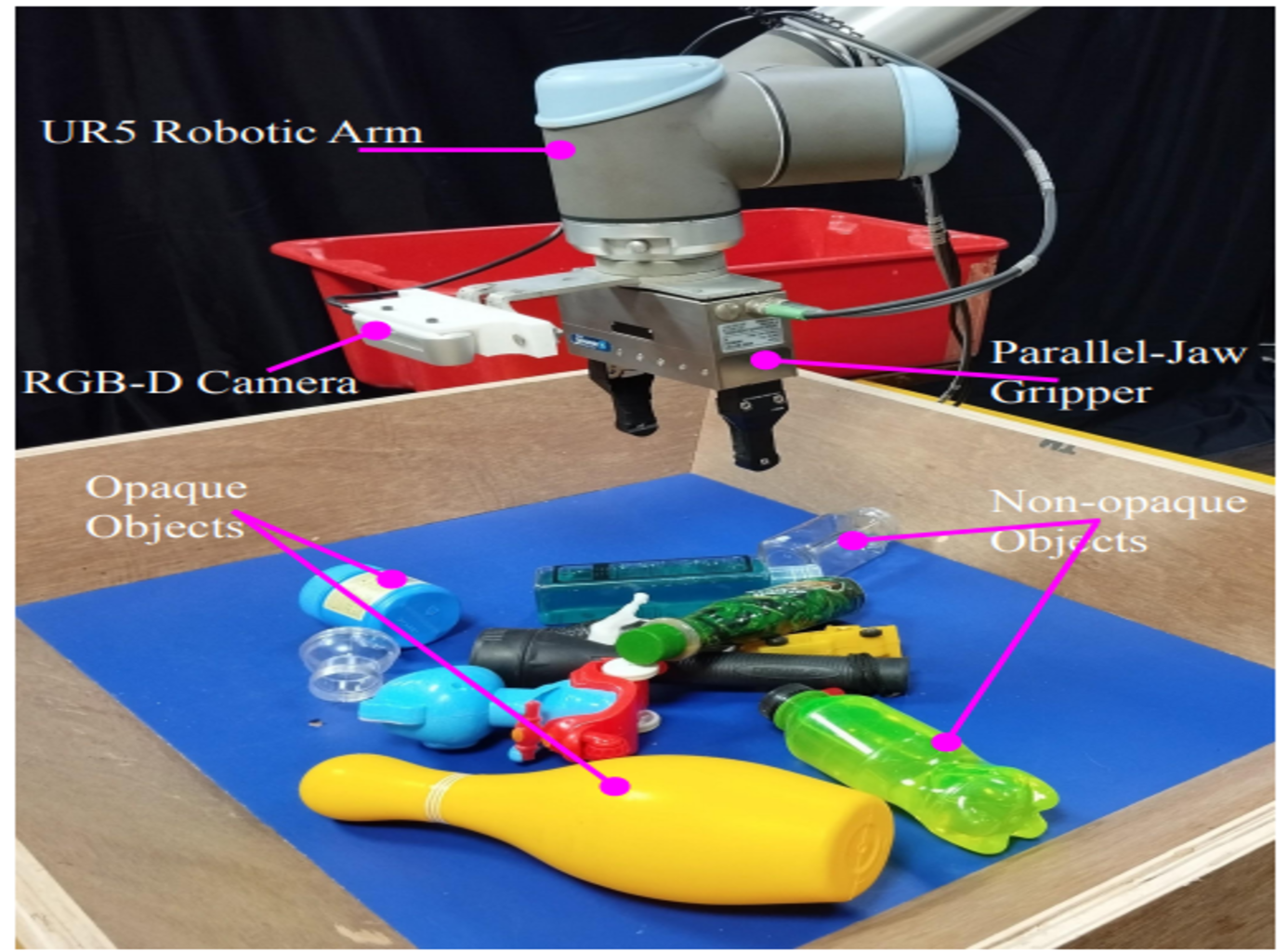 Bin-picking of novel objects through category-agnostic-segmentation: RGB mattersPrem Raj, Sachin Bhadang, Gaurav Chaudhary, and 2 more authorsIn 2023 Seventh IEEE International Conference on Robotic Computing (IRC), 2023
Bin-picking of novel objects through category-agnostic-segmentation: RGB mattersPrem Raj, Sachin Bhadang, Gaurav Chaudhary, and 2 more authorsIn 2023 Seventh IEEE International Conference on Robotic Computing (IRC), 2023This paper addresses category-agnostic instance segmentation for robotic manipulation, focusing on segmenting objects independent of their class to enable versatile applications like bin-picking in dynamic environments. Existing methods often lack generalizability and object-specific information, leading to grasp failures. We present a novel approach leveraging objectcentric instance segmentation and simulation-based training for effective transfer to real-world scenarios. Notably, our strategy overcomes challenges posed by noisy depth sensors, enhancing the reliability of learning. Our solution accommodates transparent and semi-transparent objects which are historically difficult for depth-based grasping methods. Contributions include domain randomization for successful transfer, our collected dataset for warehouse applications, and an integrated framework for efficient bin-picking. Our trained instance segmentation model achieves state-of-the-art performance over WISDOM public benchmark [1] and also over the custom-created dataset. In a real-world challenging bin-picking setup our bin-picking framework method achieves 98% accuracy for opaque objects and 97% accuracy for non-opaque objects, outperforming the state-of-theart baselines with a greater margin.
@inproceedings{raj2023bin, title = {Bin-picking of novel objects through category-agnostic-segmentation: RGB matters}, author = {Raj, Prem and Bhadang, Sachin and Chaudhary, Gaurav and Behera, Laxmidhar and Sandhan, Tushar}, booktitle = {2023 Seventh IEEE International Conference on Robotic Computing (IRC)}, pages = {231--238}, year = {2023}, organization = {IEEE}, } -
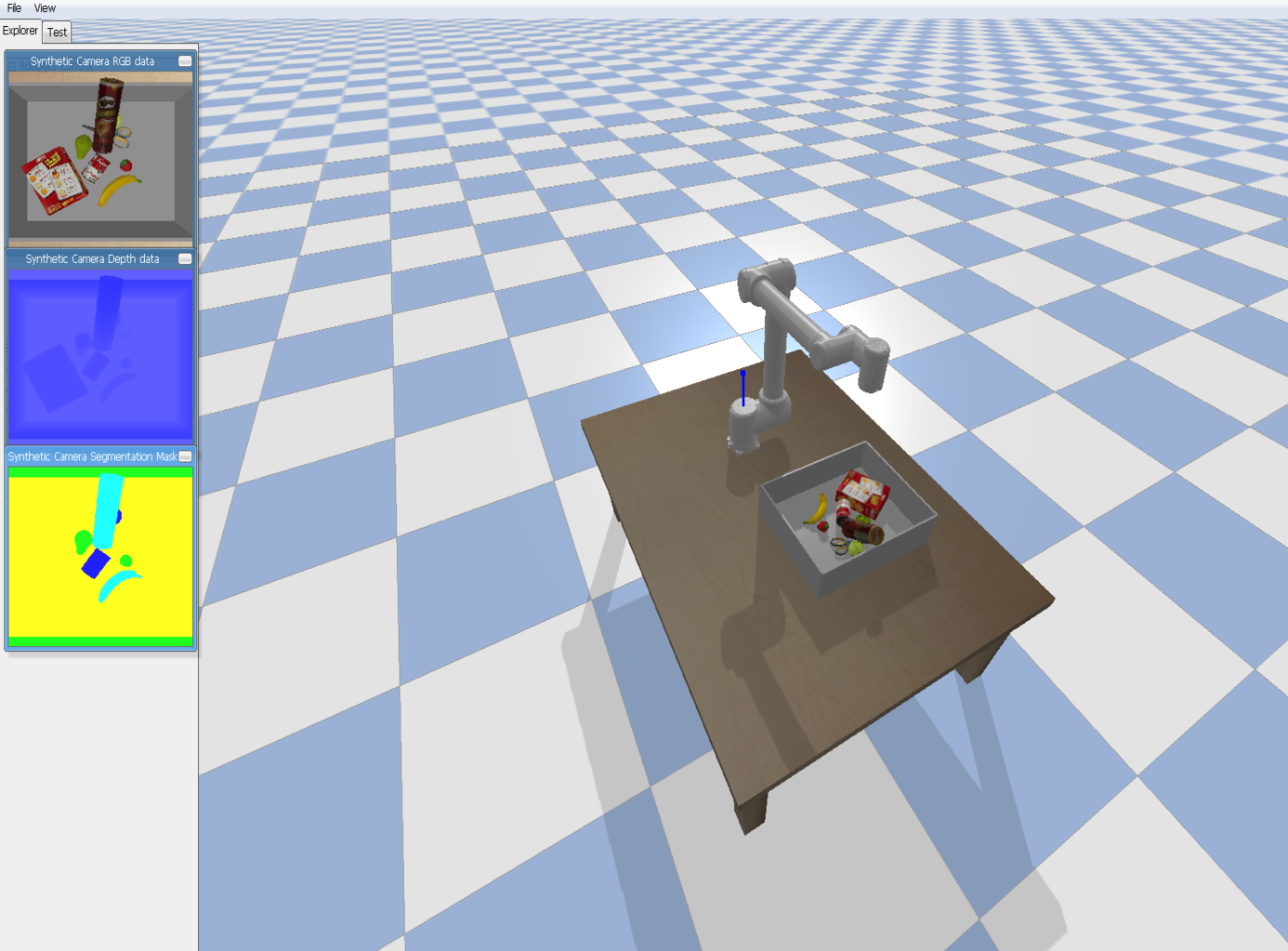 Active perception system for enhanced visual signal recovery using deep reinforcement learningGaurav Chaudhary, Laxmidhar Behera, and Tushar SandhanIn ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023
Active perception system for enhanced visual signal recovery using deep reinforcement learningGaurav Chaudhary, Laxmidhar Behera, and Tushar SandhanIn ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023Deep neural networks have demonstrated excellent object detection and segmentation performance from RGB data. However, these models can only recognize and predict segmentation masks with great accuracy when RGB data have sufficient information about the objects of interest. In this paper, we suggest an intelligent, active perception system that can adjust its 3D position to improve signal acquisition. The segmentation score of cluttered scene is improved a lot due to this proposed system, which can also enhance grasp pose detection for the robotic manipulator. The ResNet-50 backbone of the proposed perception system is initialized using pre-trained weights to extract a latent state from an RGB image of the cluttered scene. A Reinforcement Learning (RL) agent uses these retrieved states to reposition the visual perception system for enhancement of the underlying computer vision tasks such as segmentation of the cluttered scene. Our trained RL agent can anticipate the better position of the visual perception system, which ensures enhanced signal recovery. The effectiveness of the proposed approach is tested in a pybullet simulation environment.
@inproceedings{chaudhary2023active, title = {Active perception system for enhanced visual signal recovery using deep reinforcement learning}, author = {Chaudhary, Gaurav and Behera, Laxmidhar and Sandhan, Tushar}, booktitle = {ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, pages = {1--5}, year = {2023}, organization = {IEEE}, }
2016
- Tracking control of parallel manipulator with 3-DOFGaurav Chaudhary and Jyoti OhriInternational Journal of Advanced Technology and Engineering Exploration, 2016
- 3-DOF Parallel manipulator control using PID controllerGaurav Chaudhary and Jyoti OhriIn 2016 IEEE 1st International Conference on Power Electronics, Intelligent Control and Energy Systems (ICPEICES), 2016